
Machine Learning
Code Snippets
Summary
In questo post, che aggiornerò con il tempo, riporterò snippets di codice con le classi e metodi (di librerie come scikit-learn, numpy, matplotlib, etc.) più utili per progetti di ML. Poiché, non utilizzando per certi periodi alcune di queste funzioni la mia memoria decide di formattare tutto, ho deciso di mantenere traccia di questi importanti strumenti in questa pagina. Spero possa essere d’aiuto a qualcuno quanto lo è per me…
Data Pre-Processing
> Import a Dataset from 'csv' file
import numpy as np import pandas as pd dataset = pd.read_csv('name_file.csv') X = dataset.iloc[:,:-1].values y = dataset.iloc[:,[-1]].values
Il metodo “read_csv” ha molte funzioni, tra cui, header, delimiter, quoting, etc.
> Missing Data (data munging)
from sklearn.preprocessing import Imputer imputer = Imputer(missing_values='NaN', strategy='mean', axis=0) X[:,m] = imputer.fit_transform(X[:,m])
> Encode Categorical Data
from sklearn.preprocessing import LabelEncoder labelencoder_X = LabelEncoder() X[:,m] = labelencoder_X.fit_transform(X[:,m])
Crea delle etichettature numeriche. Ex: collina, montagna e mare —> 0, 1, 2
from sklearn.preprocessing import LabelBinarizer labelbinarizer_X = LabelBinarizer() X[:,m] = labelbinarizer_X.fit_transform(X[:,m])
Crea un vettore “OneHotEncoded”. Ex: collina, montagna e mare –> [[1,0,0], [0, 1, 0], [0, 1, 0]]
from sklearn.preprocessing import OneHotEncoder onehotencoder = OneHotEncoder(categorical_features=[m]) X = onehotencoder.fit_transform(X).toarray()
Come “LabelBinarizer” crea un vettore “OneHotEncoded”, ma funziona solo con dati multi-colonna. Si seleziona la colonna da trasformare durante la creazione dell’istanza e poi si passa direttamente tutta la matrice di dati. Dummy Encoding: eliminare sempre una colonna di features. X = X[:,1:].
> Splitting the Dataset
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
> Feature Scaling
from sklearn.preprocessing import StandardScaler sc_X = StandardScaler() X = sc_X.fit_transform(X)

from sklearn.preprocessing import Normalizer nr_X = Normalizer() X = nr_X.fit_transform()
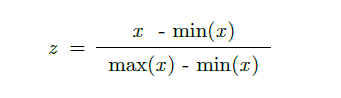
Plotting Data
> Scatter Plot with Second Order Regression Line
import matplotlib.pyplot as plt # create a canvas plt.figure(figsize=(8,8)) # scatter plot plt.scatter(X, y, s=45, marker='o', c='blue') # fit a second order z = np.polyfit(X, y, 2) # create a function p = np.poly1d(z) # create a number of points x = np.linspace(0, 1.0, 100) # plot the line plt.plot(x,p(x),c = 'r', linewidth=1, dashes=[6, 2]) plt.title('test') plt.xlabel('xlabel') plt.ylabel('y_kabel') plt.text(0, 1, '$y = 0.44x^{2} + 0.17x + 0.22$', fontsize=12) plt.text(0, 0.95, 'r = 0.81', fontsize=12) # limit x and y axis plt.xlim((0,1)) plt.ylim((0,1)) # save the plot with a png file plt.savefig('scatter_test_set.png', dpi=300, transparent=True) # show plot plt.legend() plt.show()
> Different Types of Plots
- Histograms
plt.hist(X, bins=20, color='red')
- Boxplot
import seaborn as sns sns.boxplot(X)
- Distribution and Histogram
sns.distplot(X)
- Violin Plot
sns.violinplot(X)
- Cumulative Plot
sns.kdeplot(X, cumulative=True)
> Plot Images
- Display a single figure
plt.imshow(image)
- Display a Multiple Figures (first method)
n = 0 nrows = 5 ncols = 5 # create a plot with a grid of 5x5 sub-plots (ax) fig, ax = plt.subplots(nrows,ncols,sharex=True,sharey=True, figsize=(18,18)) for row in range(nrows): for col in range(ncols): # use indexes to select sub-plots rows and columns ax[row,col].imshow(img[n]) # show grid ax.grid() ax[row,col].set_title("title_number {}".format(n)) n += 1
- Display a Multiple Figures (second method)
n = 20 # how many images we are gonna display plt.figure(figsize=(20, 4)) for i in range(n): # iterate on sub-plots ax = plt.subplot(2, n/2, i + 1) plt.imshow(X_test[i].reshape(28, 28)) plt.gray() ax.get_xaxis().set_visible(True) ax.get_yaxis().set_visible(False) plt.show()
- Display a Multiple Figures (third method)
fig, axes = plt.subplots(r, c, figsize=(15,15)) axes = axes.flatten() for img_batch, label_batch, ax in zip(images_batch[0], images_batch[1], axes): ax.imshow(img_batch) ax.grid() ax.set_title('Class: {}'.format(classes[np.argmax(label_batch)])) plt.tight_layout() plt.show()
Regression Models
> Simple/Multiple Linear Regression
from sklearn.linear_model import LinearRegression regressor = LinearRegression() regreessor.fit(X_train, y_train) y_pred = regressor.predict(X_test)
È praticamente equivalente ad utilizzare np.polyfit(X, y, 1); utilizzano entrambi la minimizzazione ai minimi quadrati per trovare “m” e “q”.
Se si utilizza un vettore X multidimensionale (più di una feature) si otterrà una multiple linear regression —> y = b0 + b1*x1 + b2 * x2 + … + bn * xn
> Polynomial Regression
from sklearn.linear_model import LinearRegression from sklearn.preprocessing import PolynomialFeatures m = 3 regressor = LinearRegression() poly_reg = PolynomialFeatures(degree = m) X_poly = poly_reg.fit_transform(X) regressor.fit(X_poly, y_train) regressor.predict(poly_reg.fit_transform(X_test))
Possiamo semplicemente riutilizzare una regressione lineare andando a aggiungere al vettore X di input le sue potenze (grado “m”). La funzione infatti ha forma —> y = b0 + b1 * x1 + b2 * x1^2 + b3 * x1^3 + … + bm * x1^m
> Support Vector Regression
from sklearn.svm import SVR regressor = SVR(kernel = 'rbf') regressor.fit(X, y) y_pred = regressor.predict(sc_X.transform(np.array([[n]]) y_pred = sc_y.inverse_transform(y_pred)
Richiede lo scalamento delle variabili. Quindi dopo la predizione bisogna tornare alla range iniziale.
> Decision Tree Regression
from sklearn.tree import DecisionTreeRegressor regressor = DecisionTreeRegressor() regressor.fit(X, y)
> Random Forest Regression
from sklearn.ensemble import RandomForestRegressor n = 100 regressor = RandomForeestRegressor(n_estimatores = n) regressor.fit(X, y)
Classification Models
Tutti i modelli richiedono uno scaling iniziale. Però , a differenza della regressione non dobbiamo trasformare le predizioni.
> Logistic Regression
from sklearn.linear_model iimport LogisticRegression classifier = LogistcRegression() classifier.fit(X_tran, y_train) y_pred = classifier.predict(X_test)
> K-Nearest Neighbors
from sklearn.neighbors import KNeighborsClassifier classifier = KNeighborsClassifier(n_neighbors=n, metric='minkowiski', p=2) classifier.fit(X_train, y_train) y_pred = classifier.predict(X_test)
Con K-Neareest Neighbors bisogna scegliere quanti vicini prendere in considerazione, “n_neighbors”, e che metrica utilizzare, “p” e “metric”.
> Support Vector Machine (SVM)
from sklearn.svm import SVC classifier = SVC(kernel = 'linear') classifier.fit(X_train, y_train) y_pred = classifier.predict(X_test)
> Kernel SVM
from sklearn.svm import SVC classifier = SVC(kernel = 'rbf') classifier.fit(X_train, y_train) y_pred = classifier.predict(X_test)
Possiamo facilmente utilizzare diversi tipi di Kernel attraverso l’attributo “kernel”.
> Naive Bayes
from sklearn.naive_bayes import GaussianNB classifier = GaussianNB() classifier.fit(X_train, y_train)
> Decision Tree Classifier
from sklearn.tree import DecisionTreeClassifier classifier = DecisionTreeClassifier(criterion = 'entropy') classifier.fit(X_train, y_train)
> Random Forest Classifier
from sklearn.ensemble import RandomForestClassifier n = 100 classifier = RandomForestClassifier(n_estimators=n, criterion='entropy') classifier.fit(X_train, y_train)
> Metrics
from sklearn.metrics import confusion_matrix, f1_score, precision_score, accuracy_score, recall_score, classification_report cm = confusion_matrix(y_test, y_pred) f1 = f1_score(y_test, y_pred) precision = precision_score(y_test, y_pred) accuracy = accuracy_score(y_test, y_pred) recall = recall_score(y_test, y_pred) report = classification_report(y_test, y_pred)