
My Projects
Here you can find some of my past, future and current projects on AI and ML. They are all well organized in cards and as they are completed, I will fill (hopefully) them with all the information.
Benchmarking Multilingual Temporal Reasoning in LLMs: The Temporal Reasoning Dataset
Researchers: Vittorio Mazzia, Sandro Pollastrini, Davide Bernardi, Chiara Rubagotti, Daniele Amberti
Founded by: Amazon AGI
Published in: IWSDS 2026
Keywords: Conversational Agents, Multilingual, Temporal Reasoning
Time reasoning is a make-or-break capability for Large Language Models (LLM s) aspiring to act as reliable personal and enterprise assistants. This work introduces the Temporal Reasoning Dataset (TRD), a programmatically generated multilingual benchmark designed to evaluate temporal reasoning operational capabilities in LLM s across ten languages, with particular focus on basic operations relevant to conversational agents handling time-sensitive tasks. TRD utilizes human-curated carrier phrases to generate a resilient-to-overfitting dataset with diverse samples and controlled difficulty levels across five core task categories, each at five difficulty levels. Extensive experimentation shows consistent patterns in model performance across languages, with a strong linear decline in accuracy as task difficulty rises in reasoning-based tasks, while memorization-based tasks remain stable. Furthermore, reasoning tasks remain robust across temporal shifts, whereas memorization tasks show performance degradation. Additionally, contextual modifications to prompts influence model performance differently than human cognitive patterns.
MASSIVE-Agents: A Benchmark for Multilingual Function-Calling in 52 Languages
Researchers: Mayank Kulkarni, Vittorio Mazzia, Chris Hench, Judith Gaspers, Jack G. M. FitzGerald
Founded by: Amazon AGI
Published in: EMNLP 2025
Keywords: Conversational Agents, Multilingual, Function calling
We present MASSIVE-Agents, a new benchmark for assessing multilingual function calling across 52 languages. We created MASSIVE-Agents by cleaning the original MASSIVE dataset and then reformatting it for evaluation within the Berkeley Function-Calling Leaderboard (BFCL) framework. The full benchmark comprises 47,020 samples with an average of 904 samples per language, covering 55 different functions and 286 arguments. We benchmarked 21 models using Amazon Bedrock and present the results along with associated analyses. MASSIVE-Agents is challenging, with the top model, Nova Premier, achieving an average Abstract Syntax Tree (AST) Accuracy of 34.05% across all languages, with performance varying significantly from 57.37% for English to as low as 6.81% for Amharic. Some models, particularly smaller ones, yielded a score of zero for the more difficult languages. Additionally, we provide results from ablations using a custom 1-shot prompt, ablations with prompts translated into different languages, and comparisons based on model latency.

Privacy Preserving Data Selection for Bias Mitigation in Speech Models
Researchers: Alkis Koudounas, Eliana Pastor, Vittorio Mazzia, Manuel Giollo, Thomas Gueudre, Elisa Reale, Luca Cagliero, Sandro Cumani, Luca de Alfaro, Elena Baralis, Daniele Amberti
Founded by: Amazon AGI
Published in: ACL 2025
Keywords: End-to-End SLU, AI Fairness and Biases, Explainable AI, Natural Language Processing
Effectively selecting data from population subgroups where a model performs poorly is crucial for improving its performance. Traditional methods for identifying these subgroups often rely on sensitive information, raising privacy issues. Additionally, gathering such information at runtime might be impractical. This paper introduces a cost-effective strategy that addresses these concerns. We identify underperforming subgroups and train a model to predict if an utterance belongs to these subgroups without needing sensitive information. This model helps mitigate bias by selecting and adding new data, which is labeled as challenging, for re-training the speech model. Experimental results on intent classification and automatic speech recognition tasks show the effectiveness of our approach in reducing biases and enhancing performance, with improvements in reducing error rates of up to 39% for FSC, 16% for ITALIC, and 22% for LibriSpeech.
Detecting and Mitigating Challenges in Zero-Shot Video Summarization with Video LLMs
Researchers: Luca Cagliero, Lorenzo Vaiani, Eliana Pastor, Alkis Koudounas, Elena Baralis, Vittorio Mazzia, Sandro Pollastrini, Thomas Gueudre, Manuel Giollo, Daniele Amberti, Yue Wu
Founded by: Amazon AGI
Published in: ACL 2025
Keywords: Multi-model LLMs, Zero-shot Video Summarization
Video summarization aims to generate a condensed textual version of an original video. Summaries may consist of either plain text or a shortlist of salient events, possibly including temporal or spatial references. Video Large Language Models (VLLMs) exhibit impressive zero-shot capabilities in video analysis. However, their performance varies significantly according to the LLM prompt, the characteristics of the video, and the properties of the training data and LLM architecture. In this work, we thoroughly evaluate the zero-shot summarization performance of four state-of-the-art open-source VLLMs specifically designed to address spatial and temporal reasoning. In light of the detected summarization issues, we propose different cost-effective mitigation strategies, based on Chain-of-Thought prompting, that involve the injection of knowledge extracted by external, lightweight models. To perform the VLLM evaluation, we design a new video summarization benchmark consisting of 100 videos with varying characteristics in terms of domain, duration, and spatio-temporal properties. Videos are manually annotated by three independent human experts with plain text, event-based, and spatio-temporal summaries. The experimental evaluation shows that VLLMs significantly benefit from prompting a list of recognized actions, whereas injecting automatically recognized objects and scene changes respectively improve spatially contextualized and event-based summaries in specific cases.

The Amazon Nova Family of Models
Researchers: Amazon Artificial General Intelligence
Founded by: Amazon AGI
Published in: Amazon Technical Reports
Keywords: Foundational Models
We present Amazon Nova, a new generation of state-of-the-art foundation models that deliver frontier intelligence and industry-leading price performance. Amazon Nova Pro is a highly capable multimodal model with the best combination of accuracy, speed, and cost for a wide range of tasks. Amazon Nova Lite is a low-cost multimodal model that is lightning fast for processing images, video, documents and text. Amazon Nova Micro is a text-only model that delivers our lowest-latency responses at very low cost. Amazon Nova Canvas is an image generation model that creates professional grade images with rich customization controls. Amazon Nova Reel is a video generation model offering high-quality outputs, customization, and motion control. Our models were built responsibly and with a commitment to customer trust, security, and reliability. We report benchmarking results for core capabilities, agentic performance, long context, functional adaptation, runtime performance, and human evaluation.

Towards Comprehensive Subgroup Performance Analysis in Speech Models
Researchers: Alkis Koudounas, Eliana Pastor, Giuseppe Attanasio, Vittorio Mazzia, Manuel Giollo, Thomas Gueudre, Elisa Reale, Luca Cagliero, Sandro Cumani, Luca de Alfaro, Elena Baralis, Daniele Amberti
Founded by: Amazon AGI
Published in: IEEE/ACM Transactions on Audio, Speech, and Language Processing
Keywords: End-to-End SLU, AI Fairness and Biases, Explainable AI, Natural Language Processing
The evaluation of spoken language understanding (SLU) systems is often restricted to assessing their global performance or examining predefined subgroups of interest. However, a more detailed analysis at the subgroup level has the potential to uncover valuable insights into how speech system performance differs across various subgroups. In this work, we identify biased data subgroups and describe them at the level of user demographics, recording conditions, and speech targets. We propose a new task-, model- and dataset-agnostic approach to detect significant intra- and cross-model performance gaps. We detect problematic data subgroups in SLU models by leveraging the notion of subgroup divergence. We also compare the outcome of different SLU models on the same dataset and task at the subgroup level. We identify significant gaps in subgroup performance between models different in size, architecture, or pre-training objectives, including multi-lingual and mono-lingual models, yet comparable to each other in overall performance. The results, obtained on two SLU models, four datasets, and three different tasks–intent classification, automatic speech recognition, and emotion recognition–confirm the effectiveness of the proposed approach in providing a nuanced SLU model assessment.

Life-Long Editing of Retrieval Augmented Large Language Models
Researchers: Vittorio Mazzia, Alessandro Pedrani, Andrea Caciolai, Kay Rottmann, Davide Bernardi, Daniele Amberti
Founded by: Amazon AGI
Published in: Internal corporate conference
Keywords: Deep Learning, Knowledge Editing, Life-long Learning
Large language models (LLMs) augmented with non-parametric memory enable the
development of systems that transcend the limitations imposed by the knowledge
encapsulated in parameters, going beyond training data. Nevertheless, the models
behind these systems are always subject to errors, and real-world scenarios require
effective tools to continuously adjust predictions to refine their accuracy over time.
Knowledge editing (KE) has emerged as an area of research to enable reliable,
data-efficient, and fast changes to a pre-trained target model. In this work, we
adopt a radically different approach, editing the retriever model rather than directly
manipulating the LLM. This approach not only minimizes regressions, but also
facilitates continuous editing without requiring direct modifications to the larger
model and allows quick rollbacks. We study a scenario in which a LLM acts as
an agent, orchestrating API calls while a retriever provides relevant examples. We
introduce two novel and complementary editing techniques that allow editing the
overall system in a continuous manner, while minimizing regressions over time.

Leveraging Confidence Models for Identifying Challenging Data Subgroups in Speech Models
Researchers: Alkis Koudounas, Eliana Pastor, Vittorio Mazzia, Manuel Giollo, Thomas Gueudre, Elisa Reale, Giuseppe Attanasio, Luca Cagliero, Sandro Cumani, Luca De Alfaro, Elena Baralis, Daniele Amberti
Founded by: Amazon AGI
Published in: ICASSP 2024
Code: GitHub Repository
Keywords: End-to-End SLU, AI Fairness and Biases, Explainable AI, Natural Language Processing

Temporal Reasoning Limits in LLMs as Agents
hend the world around us. As humans, we possess an innate sense of temporal
awareness, enabling us to plan, reflect on past occurrences, and anticipate future
events with varying time horizons. This robust capacity for temporal reasoning
is equally vital for an LLM-based agent, as it navigates a diverse array of tasks
and interactions. Indeed, the manipulation of time and date information extends to
numerous domains, and an LLM’s proficiency in this area determines its overall
utility as an assistant. Whether scheduling appointments, calculating durations,
or interpreting historical timelines, the efficient handling of temporal data is a
critical asset for an LLM to seamlessly support its users in their endeavors.

Knowledge Editing of Neural Networks
Deep neural networks are becoming increasingly pervasive in academia and industry, matching and surpassing human performance on a wide variety of fields and related tasks. However, just as humans, even the largest artificial neural networks make mistakes, and once-correct predictions can become invalid as the world progresses in time. Augmenting datasets with samples that account for mistakes or up-to-date information has become a common workaround in practical applications. However, the well-known phenomenon of catastrophic forgetting poses a challenge in achieving precise changes in the implicitly memorized knowledge of neural network parameters, often requiring a full model re-training to achieve desired behaviors. That is expensive, unreliable, and incompatible with the current trend of large self-supervised pre-training, making it necessary to find more efficient and effective methods for adapting neural network models to changing data. To address this need, knowledge editing is emerging as a novel area of research that aims to enable reliable, data-efficient, and fast changes to a pre-trained target model, without affecting model behaviors on previously learned tasks.

Back-to-Bones: Rediscovering the Role of Backbones in Domain Generalization
Researchers: Simone Angarano, Mauro Martini, Francesco Salvetti, Vittorio Mazzia, Marcello Chiaberge
Founded by: Service Robotics Lab (PIC4SeR) of Politecnico di Torino, SmartData@Polito
Published in: Pattern Recognition
Code: GitHub Repository
Keywords: Deep Learning, Domain Generalization, Self-Attention
Domain Generalization (DG) studies the capability of a deep learning model to generalize to out-of-training distributions. In the last decade, literature has been massively filled with training methodologies that claim to obtain more abstract and robust data representations to tackle domain shifts. Recent research has provided a reproducible benchmark for DG, pointing out the effectiveness of naive empirical risk minimization (ERM) over existing algorithms. Nevertheless, researchers persist in using the same outdated feature extractors, and little to no attention has been given to the effects of different backbones yet. In this paper, we go “back to the backbones”, proposing a comprehensive analysis of their intrinsic generalization capabilities, which so far have been overlooked by the research community. We evaluate a wide variety of feature extractors, from standard residual solutions to transformer-based architectures, finding an evident linear correlation between large-scale single-domain classification accuracy and DG capability. Our extensive experimentation shows that by adopting competitive backbones in conjunction with effective data augmentation, plain ERM outperforms recent DG solutions and achieves state-of-the-art accuracy. Moreover, our additional qualitative studies reveal that novel backbones give more similar representations to same-class samples, separating different domains in the feature space. This boost in generalization capabilities leaves marginal room for DG algorithms. It suggests a new paradigm for investigating the problem, placing backbones in the spotlight and encouraging the development of consistent algorithms on top of them. The code is available at https://github.com/PIC4SeR/Back-to-Bones.

Exploring Subgroup Performance in End-to-End Speech Models
Researchers: Alkis Koudounas, Eliana Pastor, Giuseppe Attanasio, Vittorio Mazzia, Manuel Giollo, Thomas Gueudre, Luca Cagliero, Luca de Alfaro, Elena Baralis, Daniele Amberti
Founded by: Amazon Alexa NU
Published in: ICASSP 2023
Code: GitHub Repository
Keywords: End-to-End SLU, AI Fairness and Biases, Explainable AI, Natural Language Processing
In real-word large end-to-end spoken language understanding models, fairness is not obvious, and biases are always hidden in the training data. This joint research collaboration between Politecnico di Torino and Amazon Alexa AI-NLU aims at developing tools and methodologies to discover and mitigate biases of e2e SLU models.

Real Time Single Image Super-Resolution at the Edge
Researchers: Vittorio Mazzia, Francesco Salvetti, Simone Angarano, Mauro Martini
Founded by: Service Robotics Lab (PIC4SeR) of Politecnico di Torino
Published in: Engineering Applications of Artificial Intelligence
Code: GitHub Repository
Keywords: Deep Learning, Single Image Super-Resolution, Edge AI, Computer Vision
Single image super-resolution (SISR) can be useful to different domains and field of application. We concentrate our research to make these algorithms light-weight and computationally efficient to embedded systems and low-power devices.

Attention Driven Global Path Planning
Teach a neural network to plan with what it perceives.

Deep Learning for Global Path Planning Generation
Researchers: Vittorio Mazzia, Diego Aghi, Francesco Salvetti, Marcello Chiaberge
Founded by: Service Robotics Lab (PIC4SeR) of Politecnico di Torino, SmartData@Polito
Published in: Computers and Electronics in Agriculture
Code: GitHub Repository
Keywords: Deep Learning, Autonomous Navigation, Global Path Planning
Agriculture 3.0 and 4.0 have gradually introduced service robotics and automation into several agricultural processes, mostly improving crops quality and seasonal yield. Row-based crops are the perfect settings to test and deploy smart machines capable of monitoring and manage the harvest. In this context, global path planning is essential either for ground or aerial vehicles, and it is the starting point for every type of mission plan. Nevertheless, little attention has been currently given to this problem by the research community and global path planning automation is still far to be solved. In order to generate a viable path for an autonomous machine, the presented research proposes a feature learning fully convolutional model capable of estimating waypoints given an occupancy grid map. In particular, we apply the proposed data-driven methodology to the specific case of row-based crops with the general objective to generate a global path able to cover the extension of the crop completely. Extensive experimentation with a custom made synthetic dataset and real satellite-derived images of different scenarios have proved the effectiveness of our methodology and demonstrated the feasibility of an end-to-end and completely autonomous global path planner.

BabyAgent: Going Beyond Dataset
Working with “really” real world data!

Human Action Recognition at the Edge
Researchers: Vittorio Mazzia, Simone Angarano, Francesco Salvetti, Federico Angelini, Marcello Chiaberge
Founded by: Service Robotics Lab (PIC4SeR) of Politecnico di Torino
Published in: Pattern Recognition
Code: GitHub Repository
Keywords: Deep Learning, Edge AI, HAR
Deep neural networks based purely on attention have been successful across several domains, relying on minimal architectural priors from the designer. In Human Action Recognition (HAR), attention mechanisms have been primarily adopted on top of standard convolutional or recurrent layers, improving the overall generalization capability. In this work, we introduce Action Transformer (AcT), a simple, fully self-attentional architecture that consistently outperforms more elaborated networks that mix convolutional, recurrent, and attentive layers. In order to limit computational and energy requests, building on previous human action recognition research, the proposed approach exploits 2D pose representations over small temporal windows, providing a low latency solution for accurate and effective real-time performance. Moreover, we open-source MPOSE2021, a new large-scale dataset, as an attempt to build a formal training and evaluation benchmark for real-time short-time human action recognition. Extensive experimentation on MPOSE2021 with our proposed methodology and several previous architectural solutions proves the effectiveness of the AcT model and poses the base for future work on HAR.

Ultra Wideband Non-Line-of-Sight Range Mitigation
Researchers: Simone Angarano, Vittorio Mazzia, Francesco Salvetti, Giovanni Fantin, Marcello Chiaberge
Founded by: Service Robotics Lab (PIC4SeR) of Politecnico di Torino, SmartData@Polito
Published in: Engineering Applications of Artificial Intelligence
Keywords: Deep Learning, Ultra wideband, Signal Processing
Ultra-wideband (UWB) is the state-of-the-art and most popular technology for wireless localization. Nevertheless, precise ranging and localization in non-line-of-sight (NLoS) conditions is still an open research topic. Indeed, multipath effects, reflections, refractions and complexity of the indoor radio environment can easily introduce a positive bias in the ranging measurement, resulting in highly inaccurate and unsatisfactory position estimation. This article proposes an efficient representation learning methodology that exploits the latest advancement in deep learning and graph optimization techniques to achieve effective ranging error mitigation at the edge. Channel Impulse Response (CIR) signals are directly exploited to extract high semantic features to estimate corrections in either NLoS or LoS conditions. Extensive experimentation with different settings and configurations have proved the effectiveness of our methodology and demonstrated the feasibility of a robust and low computational power UWB range error mitigation.
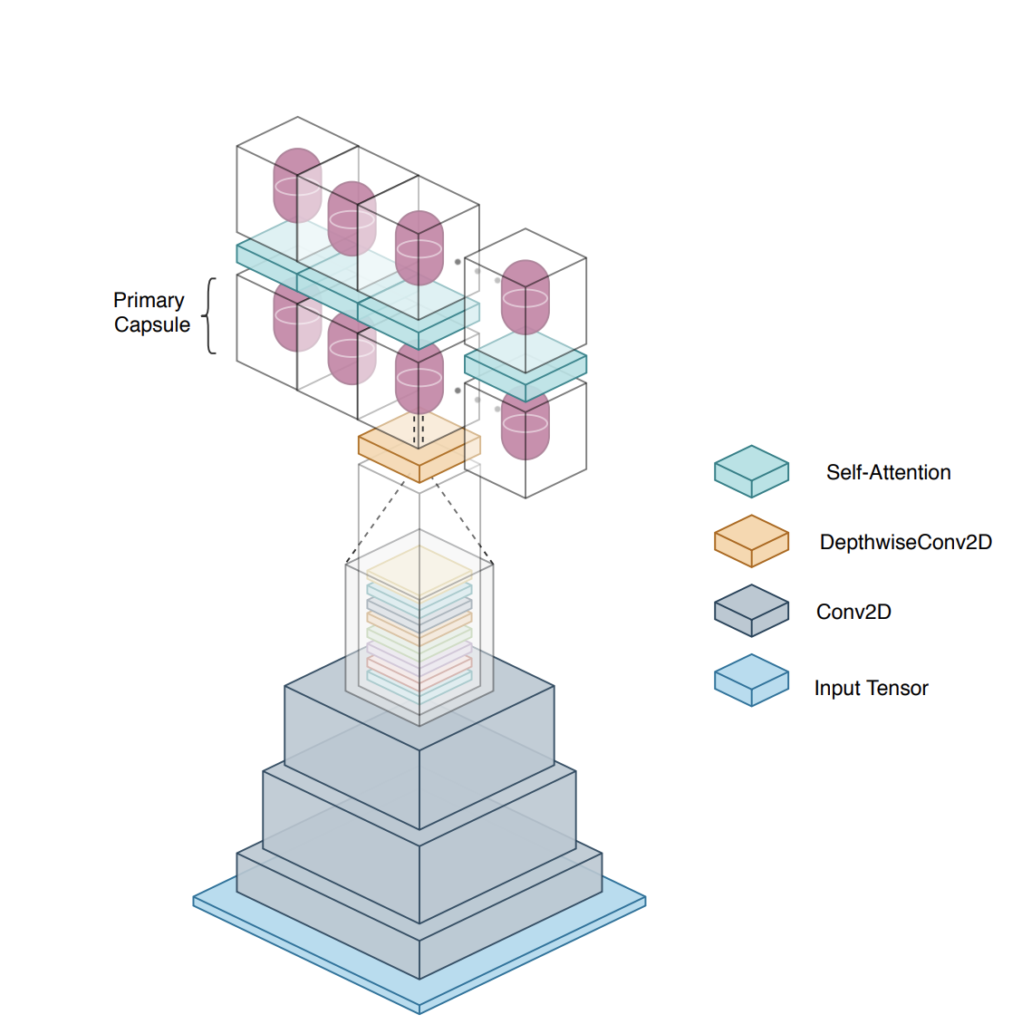
Efficient-CapsNet: Capsule Network with Self-Attention Routing
Researchers: Vittorio Mazzia, Francesco Salvetti, Marcello Chiaberge
Founded by: Service Robotics Lab (PIC4SeR) of Politecnico di Torino
Published in: Scientific Reports – Nature
Code: GitHub Repository
Keywords: Deep Learning, Visual Perseption
Deep convolutional neural networks, assisted by architectural design strategies, make extensive use of data augmentation techniques and layers with a high number of feature maps to embed object transformations. That is highly inefficient and for large datasets implies a massive redundancy of features detectors. Even though capsules networks are still in their infancy, they constitute a promising solution to extend current convolutional networks and endow artificial visual perception with a process to encode more efficiently all feature affine transformations. Indeed, a properly working capsule network should theoretically achieve higher results with a considerably lower number of parameters count due to intrinsic capability to generalize to novel viewpoints. Nevertheless, little attention has been given to this relevant aspect. In this paper, we investigate the efficiency of capsule networks and, pushing their capacity to the limits with an extreme architecture with barely 160K parameters, we prove that the proposed architecture is still able to achieve state-of-the-art results on three different datasets with only 2% of the original CapsNet parameters. Moreover, we replace dynamic routing with a novel non-iterative, highly parallelizable routing algorithm that can easily cope with a reduced number of capsules. Extensive experimentation with other capsule implementations has proved the effectiveness of our methodology and the capability of capsule networks to efficiently embed visual representations more prone to generalization.

Multi-image Super Resolution with Satellite Images
Researchers: Francesco Salvetti, Vittorio Mazzia, Marcello Chiaberge
Founded by: Service Robotics Lab (PIC4SeR) of Politecnico di Torino
Published in: Remote Sensing
Code: GitHub Repository
Keywords: Deep Learning, Multi-Image Super Resolution, Computer Vision
The goal of this research is to construct high-resolution images fusing multiple images at low resolution of the same scene. Look for PIC4SeR in the leaderboard here 😉

Camera Based Autonomous Navigation in Vineyards
Researchers: Diego Aghi, Simone Cerrato, Vittorio Mazzia, Marcello Chiaberge
Founded by: Service Robotics Lab (PIC4SeR) of Politecnico di Torino
Published in: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Keywords: Deep Learning, Computer Vision, Semantic Segmentation, Edge AI
Precision agriculture is a fast-growing field that aims at introducing affordable and effective automation into agricultural processes. Nowadays, algorithmic solutions for navigation in vineyards require expensive sensors and high computational workloads that preclude large-scale applicability of autonomous robotic platforms in real business case scenarios. From this perspective, our novel proposed control leverages the latest advancement in machine perception and edge AI techniques to achieve highly affordable and reliable navigation inside vineyard rows with low computational and power consumption. Indeed, using a custom-trained segmentation network and a low-range RGB-D camera, we are able to take advantage of the semantic information of the environment to produce smooth trajectories and stable control in different vineyards scenarios. Moreover, the segmentation maps generated by the control algorithm itself could be directly exploited as filters for a vegetative assessment of the crop status. Extensive experimentations and evaluations against real-world data and simulated environments demonstrated the effectiveness and intrinsic robustness of our methodology.

Real Time Apple Detection System using and Embedded System with a Neural Compute Engine: an Edge AI Application
Researchers: Vittorio Mazzia, Francesco Salvetti, Aleem Khaliq, Marcello Chiaberge
Founded by: Service Robotics Lab (PIC4SeR) of Politecnico di Torino
Published in: IEEE Access
Keywords: Deep Learning, Object Detection, Edge AI, Transfer Learning
Real-time apple detection in orchards is one of the most effective ways of estimating apple yields, which helps in managing apple supplies more effectively. Traditional detection methods used highly computational machine learning algorithms with intensive hardware set up, which are not suitable for infield real-time apple detection due to their weight and power constraints. In this study, a real-time embedded solution inspired from “Edge AI” is proposed for apple detection with the implementation of YOLOv3-tiny algorithm on various embedded platforms such as Raspberry Pi 3 B+ in combination with Intel Movidius Neural Computing Stick (NCS), Nvidia’s Jetson Nano and Jetson AGX Xavier. Data set for training were compiled using acquired images during field survey of apple orchard situated in the north region of Italy, and images used for testing were taken from widely used google data set by filtering out the images containing apples in different scenes to ensure the robustness of the algorithm. The proposed study adapts YOLOv3-tiny architecture to detect small objects. It shows the feasibility of deployment of the customized model on cheap and power-efficient embedded hardware without compromising mean average detection accuracy (83.64%) and achieved frame rate up to 30 fps even for the difficult scenarios such as overlapping apples, complex background, less exposure of apple due to leaves and branches. Furthermore, the proposed embedded solution can be deployed on the unmanned ground vehicles to detect, count, and measure the size of the apples in real-time to help the farmers and agronomists in their decision making and management skills.
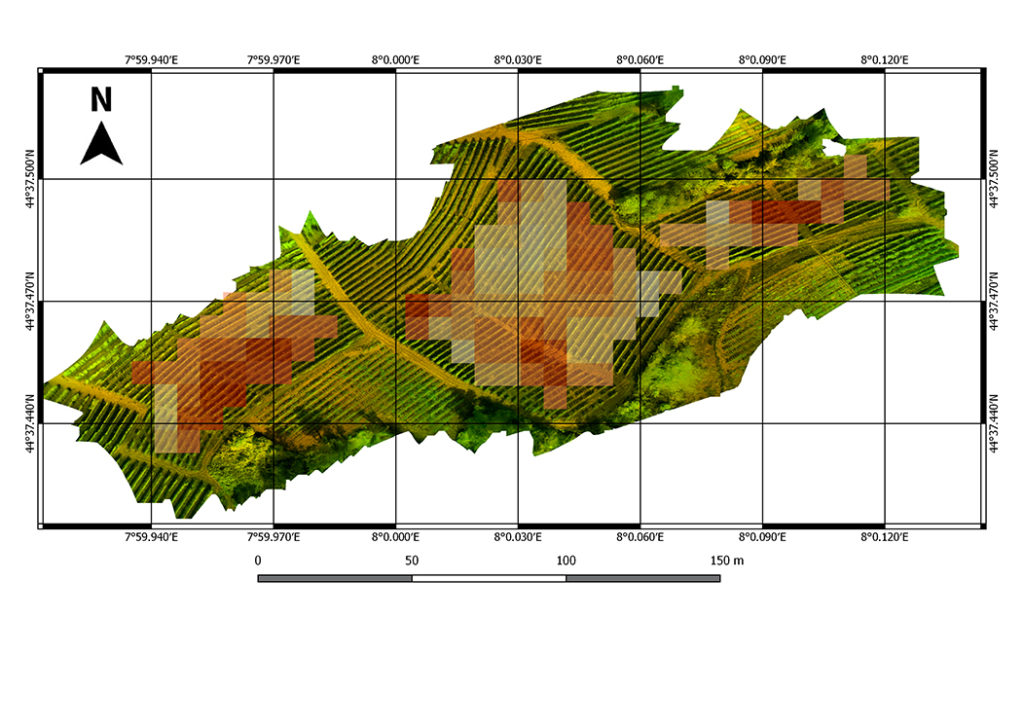
Refining Satellite Imagery by using UAV Imagery
Researchers: Vittorio Mazzia, Aleem Khaliq, Marcello Chiaberge
Founded by: Service Robotics Lab (PIC4SeR) of Politecnico di Torino
Published in: Sensors
Keywords: Deep Learning, Remote Sensing, CNN, UAV
Frequent vegetation monitoring of agriculture crops during their phenological cycle helps farmers/agronomist to perform their activities in efficient way to gain maximum yield and reduce the environmental noise caused by excessive use of chemicals. Various remote sensing platforms equipped with optical multispectral sensors such as satellite, airborne and unmanned air vehicles (UAVs) are being used in vegetation monitoring. Satellites equipped with multispectral sensors are popular due to their large coverage and temporal resolution. On the other hand, UAVs are preferred where more detailed imagery is needed while its expensive and time consuming if more frequent campaigns have to be performed. In this study, vineyard site is considered to assess the reliability of using satellite images for vegetation monitoring. Indeed, satellite imagery with decametric spatial resolution cannot describe the vegetation status at vine rows level due to the mixed nature of pixel, representing the cumulative effect of inter row terrain and vine rows. Therefore, a pixel refinement is needed to minimize this effect. In this work, a convolutional neural network (CNN) based approach is proposed to gain benefits from high resolution UAV images in order to refine the frequent moderate resolution satellite images over a vineyard.

Deep Learning Algorithms for Complex Pattern Recognition in Ultrasonic Sensors Arrays
Researchers: Vittorio Mazzia, Angelo Tartaglia, Marcello Chiaberge, Dario Gandini
Founded by: Service Robotics Lab (PIC4SeR) of Politecnico di Torino
Published in: Machine Learning, Optimization, and Data Science: 5th International Conference, LOD 2019
Keywords: Deep Learning, Ultrasonic Sensors, Machine Learning
Nowadays, applications of ultrasonic proximity sensors are limited to a post-processing of the acquired signals with a pipeline of filters and threshold comparators. This article proposes two different and novel processing methodologies, based on machine learning algorithms, that outperform classical approaches. Indeed, noisy signals and presence of thin or soundproofing objects are likely sources of false positive detections that can make traditional approaches useless and unreliable. In order to take advantage of correlations among the data, multiple parallel signals, coming from a cluster of ultrasonic sensors, have been exploited, producing a number of different features that allowed to achieve more accurate and precise predictions for object detection. Firstly, model-based learning as well as instance-based learning systems have been investigated for an independent time correlation analysis of the different signals. Particular attention has been given to the training and testing of the deep fully connected network that showed, since the beginning, more promising results. In the second part, a recurrent neural network, based on long short term memory cells, has been devised. As a result of its intrinsic nature, time correlations between successive samples are not more overlooked, further improving the overall prediction capability of the system. Finally, cutting edge training methodologies and strategies to find the different hyperparameters have been adopted in order to obtain the best results and performance from the available data.

Pixel Based Crops Classification with Satellite Images
Researchers: Vittorio Mazzia, Aleem Khaliq, Marcello Chiaberge
Founded by: Service Robotics Lab (PIC4SeR) of Politecnico di Torino
Published in: Applied Science
Keywords: Crops Classification, Deep Learning, RNN
Understanding the use of current land cover, along with monitoring change over time, is vital for agronomists and agricultural agencies responsible for land management. The increasing spatial and temporal resolution of globally available satellite images, such as provided by Sentinel-2, creates new possibilities for researchers to use freely available multi-spectral optical images, with decametric spatial resolution and more frequent revisits for remote sensing applications such as land cover and crop classification (LC&CC), agricultural monitoring and management, environment monitoring. Existing solutions dedicated to cropland mapping can be categorized based on per-pixel based and object-based. However, it is still challenging when more classes of agricultural crops are considered at a massive scale. In this paper, a novel and optimal deep learning model for pixel-based LC&CC is developed and implemented based on Recurrent Neural Networks (RNN) in combination with Convolutional Neural Networks (CNN) using multi-temporal sentinel-2 imagery of central north part of Italy, which has diverse agricultural system dominated by economic crop types. The proposed methodology is capable of automated feature extraction by learning time correlation of multiple images, which reduces manual feature engineering and modeling crop phenological stages. Fifteen classes, including major agricultural crops, were considered in this study. We also tested other widely used traditional machine learning algorithms for comparison such as support vector machine SVM, random forest (RF), Kernal SVM, and gradient boosting machine, also called XGBoost. The overall accuracy achieved by our proposed Pixel R-CNN was 96.5%, which showed considerable improvements in comparison with existing mainstream methods. This study showed that Pixel R-CNN based model offers a highly accurate way to assess and employ time-series data for multi-temporal classification tasks.

Incremental Learning for Object Detection on Embedded Systems using Machine Generated Bounding Boxes
Researchers: Vittorio Mazzia, Marcello Chiaberge
Founded by: Big Data and Data Science Lab (SmartData) of Politecnico di Torino
Published in: Internal university conference (SmartData)
Keywords: Transfer Learning, Active Learning Deep Learning, Incremental Learning, Object detection
Training object class detectors typically requires large amount of data in which images are manually annotated with bounding boxes (bbox) for every instance of each class. This is particularly true for lightweight object class detectors that progressively improve their mean average precision (mAP) increasing the number of examples available. The presented research suggests a methodology to exploit generated data from the field and a collaboration with multiple independent deep neural networks to obtain an increasingly more performing embedded model for the designated tasks.

Autonomous Navigation with Deep Reinforcement Learning at the Edge
Researchers: Enrico Sutera, Vittorio Mazzia, Francesco Salvetti, Giovanni Fantin, Marcello Chiaberge
Founded by: Service Robotics Lab (PIC4SeR) of Politecnico di Torino
Published in: Proceedings of the 13th International Conference on Agents and Artificial Intelligence-Volume 1: ICAART
Keywords: Reinforcement Learning, Deep-Q Learning, Service Robotics, A2C
Indoor autonomous navigation requires a precise and accurate localization system able to guide robots through cluttered, unstructured and dynamic environments. Ultra-wideband (UWB) technology, as an indoor positioning system, offers precise localization and tracking, but moving obstacles and non-line-of-sight occurrences can generate noisy and unreliable signals. That, combined with sensors noise, unmodeled dynamics and environment changes can result in a failure of the guidance algorithm of the robot. We demonstrate how a power-efficient and low computational cost point-to-point local planner, learnt with deep reinforcement learning (RL), combined with UWB localization technology can constitute a robust and resilient to noise short-range guidance system complete solution. We trained the RL agent on a simulated environment that encapsulates the robot dynamics and task constraints and then, we tested the learnt point-to-point navigation policies in a real setting with more than two-hundred experimental evaluations using UWB localization. Our results show that the computational efficient end-to-end policy learnt in plain simulation, that directly maps low-range sensors signals to robot controls, deployed in combination with ultra-wideband noisy localization in a real environment, can provide a robust, scalable and at-the-edge low-cost navigation system solution.
Unmanned Ground Vehicle (UGV) Detection from Unmanned Aerial Vehicle (UAV) Video Stream
Object Detection (OD) has been radically changed and improved in the past
few years by Deep Learning (DL) branch. As other computer vision tasks, such as image
classification, instance segmentation, face recognition, OD has achieved results never seen before
and it has started to become an useful tool for practical applications. This brief research aim
at assessing the potentiality of latest improvements in the field of OD with a real study case
brought by an Italian company request. More in detail, the presented study experiments a deep
learning algorithm, to recognize automatically unmanned ground vehicles (UGVs) in video
streams taken by unmanned aerial vehicles (UAVs). DL architectures are a very powerful tools
but, they also require huge amount of data and computational power. In order to speed up the
training process Amazon AWS EC2 P3 instance with NVIDIA Tesla v100 has been largely used.
Multiple general purpose graphic processing units (GP-GPUs) have been exploited in order to
parallelize and cut wall time down of the training process.

A Cost-Effective Person-Following System for Assistive Unmanned Vehicles with Deep Learning at the Edge
Researchers: Anna Boschi, Francesco Salvetti, Vittorio Mazzia, Marcello Chiaberge
Founded by: Service Robotics Lab (PIC4SeR) of Politecnico di Torino
Published by: Machines
Keywords:Computer Vision, Object Detection, Edge AI, Service Robotics
The vital statistics of the last century highlight a sharp increment of the average age of the world population with a consequent growth of the number of older people. Service robotics applications have the potentiality to provide systems and tools to support the autonomous and self-sufficient older adults in their houses in everyday life, thereby avoiding the task of monitoring them with third parties. In this context, we propose a cost-effective modular solution to detect and follow a person in an indoor, domestic environment. We exploited the latest advancements in deep learning optimization techniques, and we compared different neural network accelerators to provide a robust and flexible person-following system at the edge. Our proposed cost-effective and power-efficient solution is fully-integrable with pre-existing navigation stacks and creates the foundations for the development of fully-autonomous and self-contained service robotics applications.











