
Intro to
TensorFlow Lite
In questa breve pagina blog vediamo alcuni dei concetti e funzionalità più importanti del ToolKit TensorFlow Lite che viene distribuito insieme alla versione TensorFlow 2.0. TensorFlow Lite fa parte dei mezzi messi a disposizione dal framework per far inferenza (predire con nuovi dati) dopo che un nostro modello è stato addestrato e rifinito. Lo scopo primario è quello di portare gli algoritmi di machine learning su tutti i dispositivi con limitate capacità computazionali; una pratica sempre più utilizzata che va sotto il nome di Edge AI. Il paradigmo classico prevede che i dispositivi IoT (Microcontrollori, Raspberry Pi, …) ma anche smartphone e in generale qualsiasi dispositivo non molto performante siano principalmente delle sorgenti di acquisizione di dati. Questi poi, belli impacchettati e trasmessi in cloud vengono processati ed elaborati su server dedicati. Con l’Edge AI invece si cerca di operare sui dati tutto in locale eliminando qualsiasi problema di banda, latenza, privacy/sicurezza e portando più semplicità al sistema nel suo complesso.
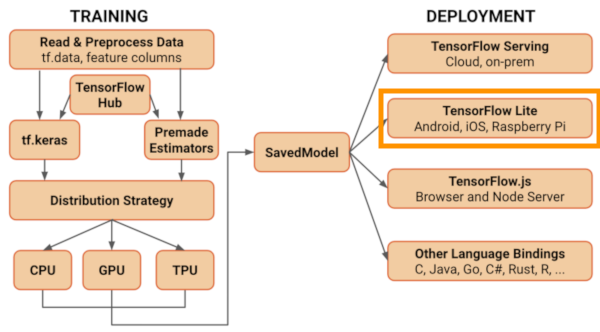

Tutto questo però si scontra con l’avere a che fare con dispositivi con limitata memoria primaria (RAM, cache), potenza computazionale, storage e in alcuni casi potenza elettrica (autonomia massima dettata dalla batteria e potenza assorbita).
Proprio per queste limitazioni nasce TensorFlow Lite che mette a disposizione diversi strumenti per ottimizzare e distribuire modelli di machine learning (praticamente solo Deep Learning 🙂 ) su dispositivi mobili e IoT. Questo formidabile ToolKit presenta principalmente due strumenti fondamentali: il convertitore (TFLite Converter) e l’interprete (TFLite Interpreter) che può essere installato indipendentemente su il dispositivo su cui vogliamo fare inferenza.
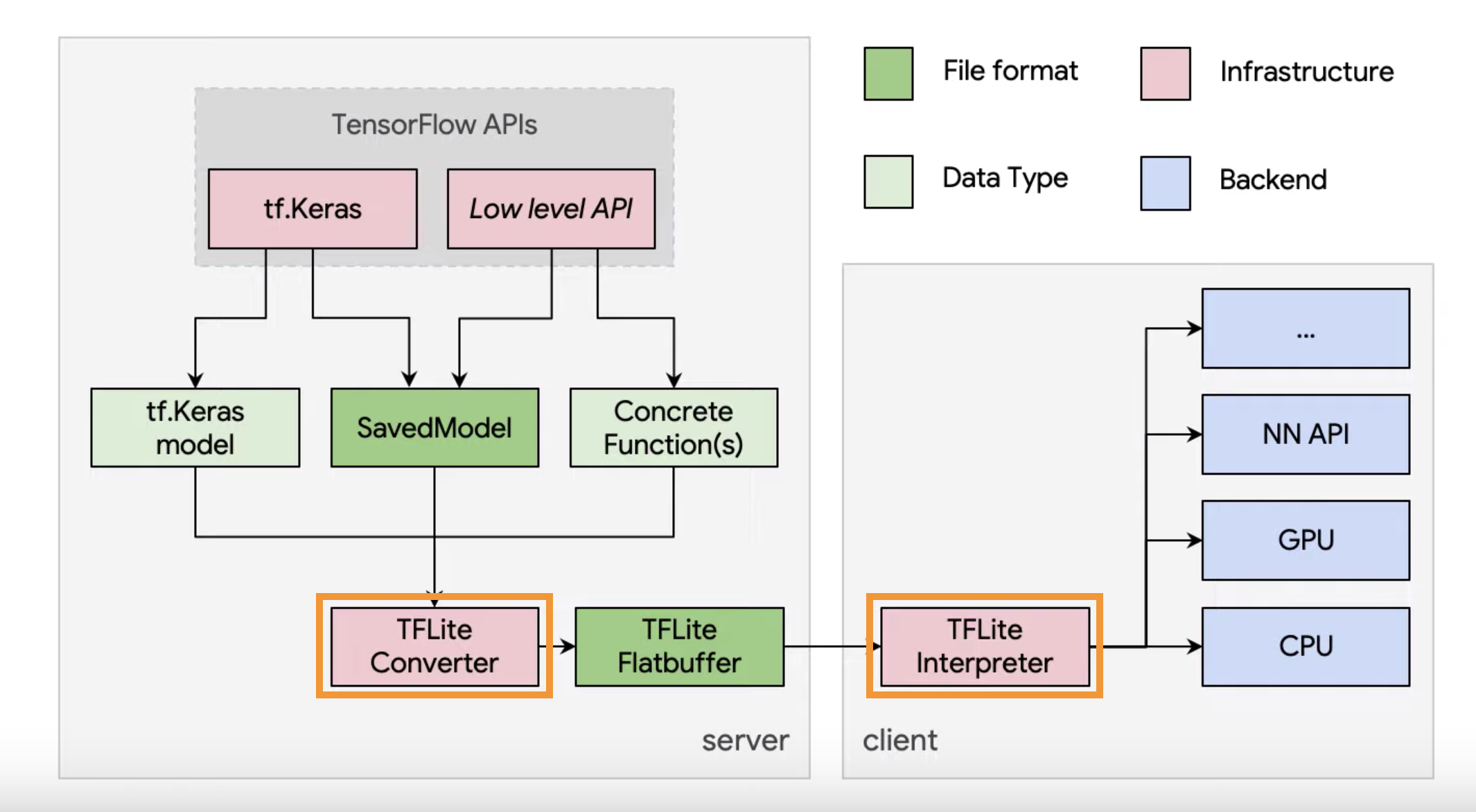
Il convertitore ha il compito principale di ottimizzare il modello riducendo le suo dimensioni e aumentando la suo velocità di esecuzione. Questo viene principalmente ottenuto con due tecniche fondamentali: model quantization e model pruning. Il primo, che è una delle più popolari tecniche di ottimizzazione, prevede di ridurre la precisione di rappresentazione del nostro modello. Per esempio possiamo convertire tutti i pesi da float 32 bit a int 8 bit (post-training quantization). Questo sicuramente andrà ad impattare sull’accuratezza del nostro modello ma restituirà un modello molto più leggero e reattivo. Oltre ai pesi, anche le attivazione dei diversi “layer” possono essere quantizzate raggiungendo velocità di inferenza ancora maggiori. Nel caso l’accuratezza del nostro modello fosse troppo degradata da questa procedura, possiamo pensare di ri-addestrare il nostro modello con questa limitazione dei pesi in mente (quantization aware training). La seconda tecnica di ottimizzazione prende il nome di model pruning e consiste nel rendere più efficiente il grafo del nostro modello. Di seguito la guida ufficiale di TensorFlow ha messo a disposizione una strategia da adottare per quando vogliamo convertire il nostro modello nel formato “.lite“

Convertire un Modello
> Solo conversione e nessuna ottimizzazione
import tensorflow as tf import pathlib # from keras model converter = tf.lite.TFLiteConverter.from_keras_model(model) # or from tf saved model converter = tf.lite.TFLiteConverter.from_saved_model(tf_path_model) # last from concrete functions converter = tf.lite.TFLiteConverter.from_concrete_funcions(tf_path_concrete_functions) # start conversion tflite_model = converter.converter() # save model tflite_model_file = pathlib.Path('./my_path') tflite_model_file.write_bytes(tflite_model)
Il convertitore può caricare un modello salvato in formato Keras (.h5) oppure in TensorFlow Saved Model: Saved Model è una serializzazione “standalone” degli oggetti di TensorFlow. Contiene il programma completo di TensorFlow includendo anche i pesi e il grafo di computazione. Non richiede il modello originale e il suo codice per funzionare. È composto da tre file:
- checkpoint: contiene i pesi orifinali
- config: architettura del modello
- proto: contiene il grafo del modello TensorFlow. Se il modello non era stato compilato prima di essere salvato, contiene solo il grafo dell’inferenza
> Convertire dalla Shell
tflite_convert -output_file = model.tflite --saved_model_dir = my_dir
tflite_convert -output_file = model.tflite --keras_model_file = model_path
> Ottimizzare solo il peso della rete
converter = tf.lite.TFLiteConverter.from_saved_model(tf_path_model) converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE] # start conversion tflite_quant_model = converter.converter()
Con “OPTIMIZE_FOR_SIZE” solo i pesi vengono convertiti. Quindi alcune operazioni saranno eseguite in FPU altre come interi. TFLite delega solo alcune operazioni sugli acceleratori hardware disponibili.
N.B. Se si assiste ad una riduzione non indifferente dell’accuratezza è meglio fare un passo indietro e ri-addestrare il modello con la precisione ridotta fin dall’inizio. Infatti, con una “quantization aware” si ottiene solitamente un modello con un’accuratezza maggiore poiché la rete è più tollerante ai valori con precisione ridotta.
> Ottimizzare il peso e la velocità
Per quantizzare anche le attivazioni dobbiamo creare un generatore per permettere al convertitore di calibrare il range dinamico delle attivazioni.
def generator() data = tfds.load() for _ in range(min_calibration_steps): image, = data.take(1) yield[image] converter = tf.lite.TFLiteConverter.from_saved_model(tf_path_model) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = tf.lite.RepresentativeDataset(generator) # optinal: force the converter to convert all activations. #If no TensorFlow Lite representation is available, it trows an error during the conversion converter.target_spec.supported_ops = [tf.liteOpsSet.TFLITE_BUILTINS_INT8] # start conversion tflite_quant_model = converter.convert()
Se ci sono certe attivazioni senza una corrispettiva rappresentazione in TensorFlow Lite il convertitore le lascia invariate. Quindi, quest’ultime sono eseguite a parte dalla CPU. Bye bye speed 🙂
Nel video qui sotto potete trovare una trattazione completa (purtroppo in inglese 🤯) con tutte le trasformazioni eseguibili con il convertitore di TF-Lite.
Inferenza con l'Interprete
Una volta ottenuto il modello convertito nel formato di TensorFlow Lite è possibile richiamare l’interprete per fare inferenza ed ottenere nuove predizioni. L’interprete può essere installato separatamente senza portarsi dietro tutta il framework di TensorFlow.
# load model and allocate tensors (allocate working memory for the model) interpreter = tf.lite.Interpreter(model_content = tflite_model) interpreter.allocate_tensors() # get input and output details input_details = interpreter.get_input_details() output_details = interpreter.get_output_details() # point the data to be used for testing and run the interpreter interpreter.set_tensor(input_details[0]['index'], input_data) # run interpreter.invoke() tflite_results = interpreter.get_tensor(output_details[0]['index'])
Oggettivamente potevano mantenere un struttura più simile a Keras e Scikit-Learn per il richiamo dell’interprete.
Esempio: Addestramento, Conversione e Inferenza
import matplotlib.pyplot as plt import pathlib import numpy as np import tensorflow as tf # dataset X_train = [-20, -15, -10, -5, 0, 5, 10, 15, 20] y_train = [-4, 5, 14, 23, 32, 41, 50, 59, 68] # build the model l0 = tf.keras.layers.Dense(units=1, input_shape=[1]) model = tf.keras.Sequential([l0]) # compile the model model.compile(loss='mean_squared_error', optimizer=tf.keras.optimizers.Adam(0.1)) # train the model history = model.fit(X_train, y_train, epochs=500) # plot the training graph plt.xlabel('Epoch Number') plt.ylabel('Loss Magnitude') plt.plot(history.history['loss']) # try to predict model.predict([100.0]) # show the two learnt variables # they will be very near 1.8 and 32 l0.get_weights() # save the beautiful trained model export_dir = 'saved_model/' tf.saved_model.save(model, export_dir) # call the converter converter = tf.lite.TFLiteConverter.from_saved_model(export_dir) tflite_model = converter.convert() tflite_model_file = pathlib.Path('converted/model.tflite') tflite_model_file.write_bytes(tflite_model) # call the interpreter to make new predictions interpreter = tf.lite.Interpreter(model_content = tflite_model) interpreter.allocate_tensors() input_details = interpreter.get_input_details() output_details = interpreter.get_output_details() # make inference on random numbers input_shape = input_details[0]['shape'] inputs, outputs = [], [] for _ in range(100): input_data = np.array(np.random.random_sample(input_shape), dtype=np.float32) interpreter.set_tensor(input_details[0]['index'], input_data) interpreter.invoke() tflite_results = interpreter.get_tensor(output_details[0]['index']) tf_results = model.predict(input_data) print('Original model pred: {} | TFLite model pred: {}'.format(tf_results, tflite_results))